자기회귀(Autoregressive, AR) 모델 2편 Visual Autoregressive Modeling
AR 모델의 확장, Visual Autoregressive Modeling

지난 인사이트에서는 자기회귀(AutoRegressive, AR) 모델이 이미지 생성에서 다시 주목받고 있는 이유를 살펴봤습니다. 흥미로운 점은 AR 모델이 본질적으로 언어모델(LLM)과 같은 구조를 공유하는 겁니다. 이 말은 곧, 텍스트뿐 아니라 이미지·음성·비디오까지 확장 가능한 멀티모달 AI의 중심 축이 될 수 있다는 뜻이죠. 실제로 멀티모달 AI 시장은 연평균 33.6%의 성장률로 폭발적으로 확대될 것으로 예상되며, 멀티모달 모델의 필요성은 점점 더 커지고 있습니다. (출처: https://www.gminsights.com/ko/industry-analysis/multimodal-ai-market) 이번 2편에서는 한 단계 더 나아가 최근 발표된 Visual Autoregressive Modeling(VAR) 논문을 중심으로 AR 모델이 어떻게 확장성을 증명했는지 알아보겠습니다. 논문 ➡ https://arxiv.org/pdf/2404.02905
왜 VAR인가?
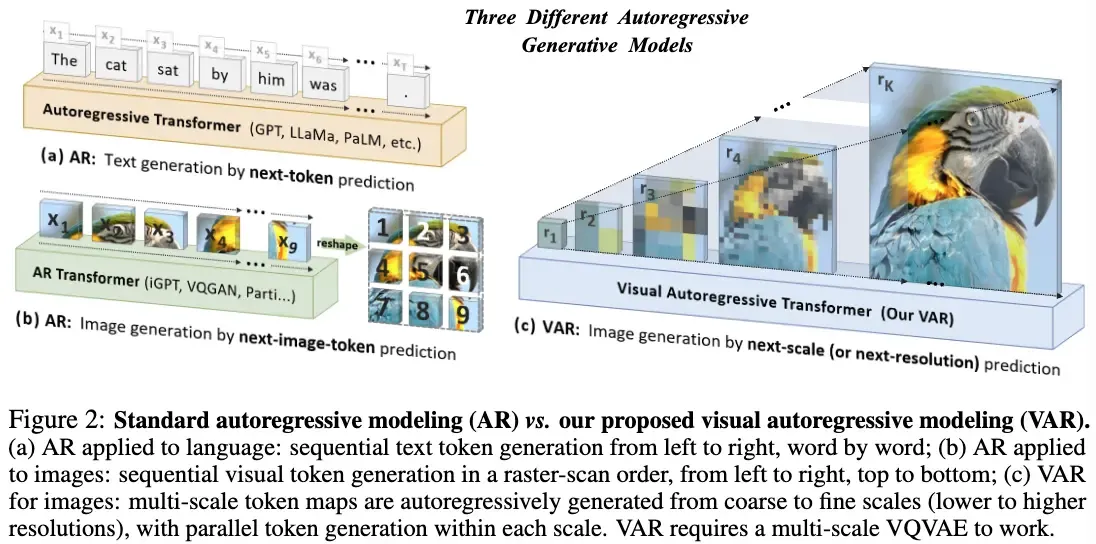
기존 자기회귀(AR) 모델은 이미지 생성을 한 줄씩 순차적으로 예측해야 했기 때문에 느리고 확장성에 한계가 있었습니다. 반면 Visual Autoregressive Modeling(VAR)은 Next-Scale Prediction이라는 새로운 방식을 도입했습니다.
- 좌→우, 상→하 래스터 스캔 대신,
- 저해상도(coarse)에서 고해상도(fine)로 점차 확대하며 이미지를 예측합니다.
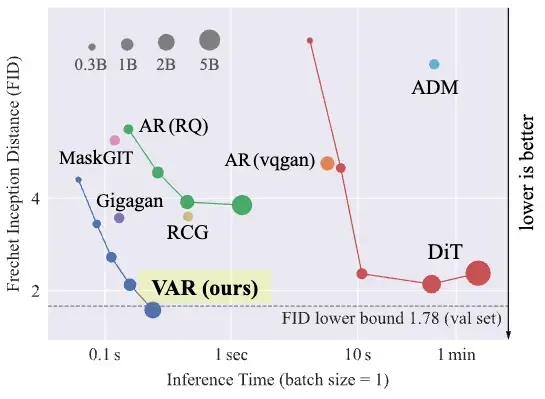
이 단순하면서도 직관적인 변화만으로, VAR는 처음으로 GPT-스타일 AR 트랜스포머가 Diffusion Transformer(DiT)를 능가하는 결과를 보여주었습니다
"이미 성공한 LLM 에 궁합이 좋은 VAR 을 결합하자!"
출처: Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction

주요 성과
- ImageNet 256×256 조건생성에서 FID 1.80, IS 356.4, AR 베이스라인 대비 20 배 빠른 추론 속도 달성
- DiT‑XL/2, L‑DiT‑3B/7B보다 우수한 품질·속도·데이터 효율·스케일링 성능
VAR의 핵심 기술 스택
VAR 개요 및 기존 AR 대비 차별점
출처: Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction
- Visual Tokenization 재고
- 단일 해상도 토큰을 1‑D로 평탄화하던 방식 → 다중 스케일 토큰 맵을 계층적으로 예측(1×1 → 2×2 → 4×4 … )
- 기존 AR은 이미지를 단일 해상도의 토큰으로 평탄화(1D 시퀀스)했기 때문에 시퀀스가 길고 비효율적이었습니다. → VAR는 다중 스케일 토큰 맵을 계층적으로 예측합니다. (16² → 32² → 64² … 식으로 점차 확장)
- 성능 향상 동일 VQVAE를 쓰더라도 AR 베이스라인 FID 18.65 → 5.22(VAR 기본형) → 1.73(2B 파라미터, CFG 적용)로 비약적 개선
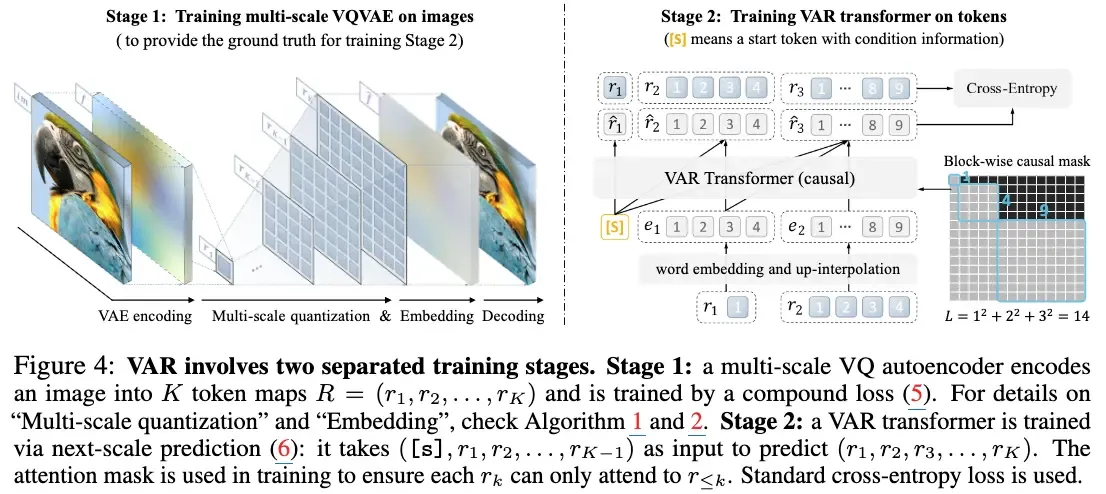
V-Tokenizer: 다중 스케일 VQ-VAE
출처: Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction
- Shared codebook based multi-scale encoding으로 고해상도까지 효율적 재구성합니다.
- codebook 일종의 visual tokenizer 벡터 양자화(vector quantization)나 임베딩 기반 모델에서 연속적인(또는 고차원) 입력을 이산적인 토큰(색인)으로 변환하기 위해 사용하는 "코드워드(codeword)"들의 집합
- VQ-GAN 구조 계승 + 확장 Encoder-Decoder는 기존 VQ-GAN 방식을 따르되, 코드북 크기와 스케일 수를 확장하여 고해상도 이미지에서도 정보 손실을 최소화했습니다.
Autoregressive Transformer
- GPT‑2 와 유사한 decoder‑only 구조 + Adaptive Layer Norm(AdaLN), RoPE·SwiGLU 없이도 스케일링 가능성 확인
- AdaLN Transformer 모델의 안정적인 학습을 돕는 중요한 정규화 기법
- RoPE (Rotary Position Embedding) 회전 변환 기반의 상대적 위치 인코딩 방식
- SwiGLU (Swish, Gated Linear Unit) 일반적인 MLP (Multi-Layer Perceptron)를 대체하는, 새로운 형태의 피드포워드 네트워크 아키텍처
- Block-wise causal mask 유지, 단 스케일 간 순차·스케일 내부 병렬 토큰 예측으로 연산량 감소
학습 전략
- ImageNet 256/512 Conditional Generation, 200–350 epoch 사전학습 → CFG ρ=2.0 미세조정
- Classifier-Free Guidance(CFG) 조건부 생성 모델(Conditional Generative Models)에서 생성된 데이터의 품질과 주어진 조건(Condition)에 대한 충실도(Fidelity)를 향상시키기 위한 기법
- Token Cross‑Entropy + Top‑k Sampling, CFG로 품질·안정성 동시 확보
실험 결과 및 성능 분석
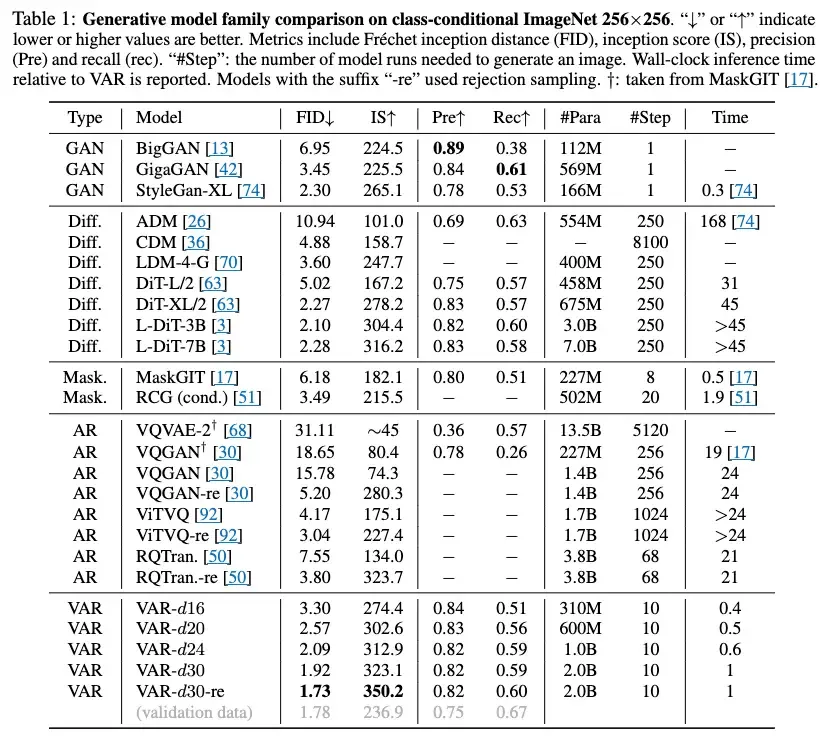
📊 정량적 평가
- ImageNet 256×256 조건 생성에서 FID 1.73 / IS 350.2 달성
- AR 베이스라인 대비 약 20배 빠른 추론
- 확장성 측면에서 L-DiT 3B/7B 모델보다 낮은 FID를 기록
출처: Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction
Frechet Inception Distance
🎨 정성적 평가

출처: Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction

출처: Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction

출처: Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction
- 디테일이 살아있는 이미지 퀄리티
- in-painting, out-painting, class-conditional image editing 등의 다른 task 에서도 높은 성능을 보임 (zero-shot)
VAR의 의미와 시사점
- AR 재부흥 Diffusion 시대를 넘어 AR 계열이 SOTA 경쟁력 확보
- LLM‑like 특성 Scaling Law/Zero‑shot generalization → multimodal based 모델로 확장 가능성 높음
- Computer Vision Zero-shot task 수행 가능 (Generation)
- 오픈소스 생태계 코드·체크포인트 공개 → 커뮤니티 확산, 후속 Infinite‑Vocabulary Tokenizer 연구 촉진
한계와 향후 과제
- 계산 자원 다중 스케일 토큰화와 수십억 파라미터로 인해 메모리와 컴퓨팅 부담이 큼
- 속도 Diffusion 대비 크게 개선됐지만, 아직 완전한 실시간 추론까지는 거리 있음
마무리하며
VAR는 "이미지를 단어처럼" 생성한다는 자기회귀(AR) 철학을 다중 해상도 관점으로 재정립하며 처음으로 AR 트랜스포머가 Diffusion 계열을 앞서는 성과를 달성했습니다. 이번 연구는 AR 계열 모델이 단순히 이미지 생성 성능 개선에 그치지 않고 대규모 학습과 일반화 능력을 통해 멀티모달 AI로 확장될 잠재력을 지니고 있음을 시사합니다. 향후에는 계산 효율성 개선과 실시간성 확보 다양한 데이터 유형을 통합하는 멀티모달 학습을 통해 산업 전반에서의 활용 가능성이 더욱 커질 것으로 예상됩니다. 결국 VAR는 자기회귀 기반 모델의 부활을 넘어 차세대 생성형 AI의 방향성을 제시하는 중요한 전환점이라 할 수 있습니다.




